
It’s pretty much common knowledge that you cannot use a Table Output step with a column oriented database. All those insert statements are painstakingly slow. That’s why we have bulk loaders. Not all DBMSs have a bulk load step, but the most common ones do (either as a Job entry or a Transformation step). There’s even a Vertica bulk loader, though not included with the release (note to self, create a JIRA requesting that).
This post is about PDI’s MonetDB bulk loader step. You have to define the DB connection, set the target schema and table, set a buffer size (number of rows to be sent each time, default is 100k), and insert the field mappings. So, it’s relatively easy to set up and test.
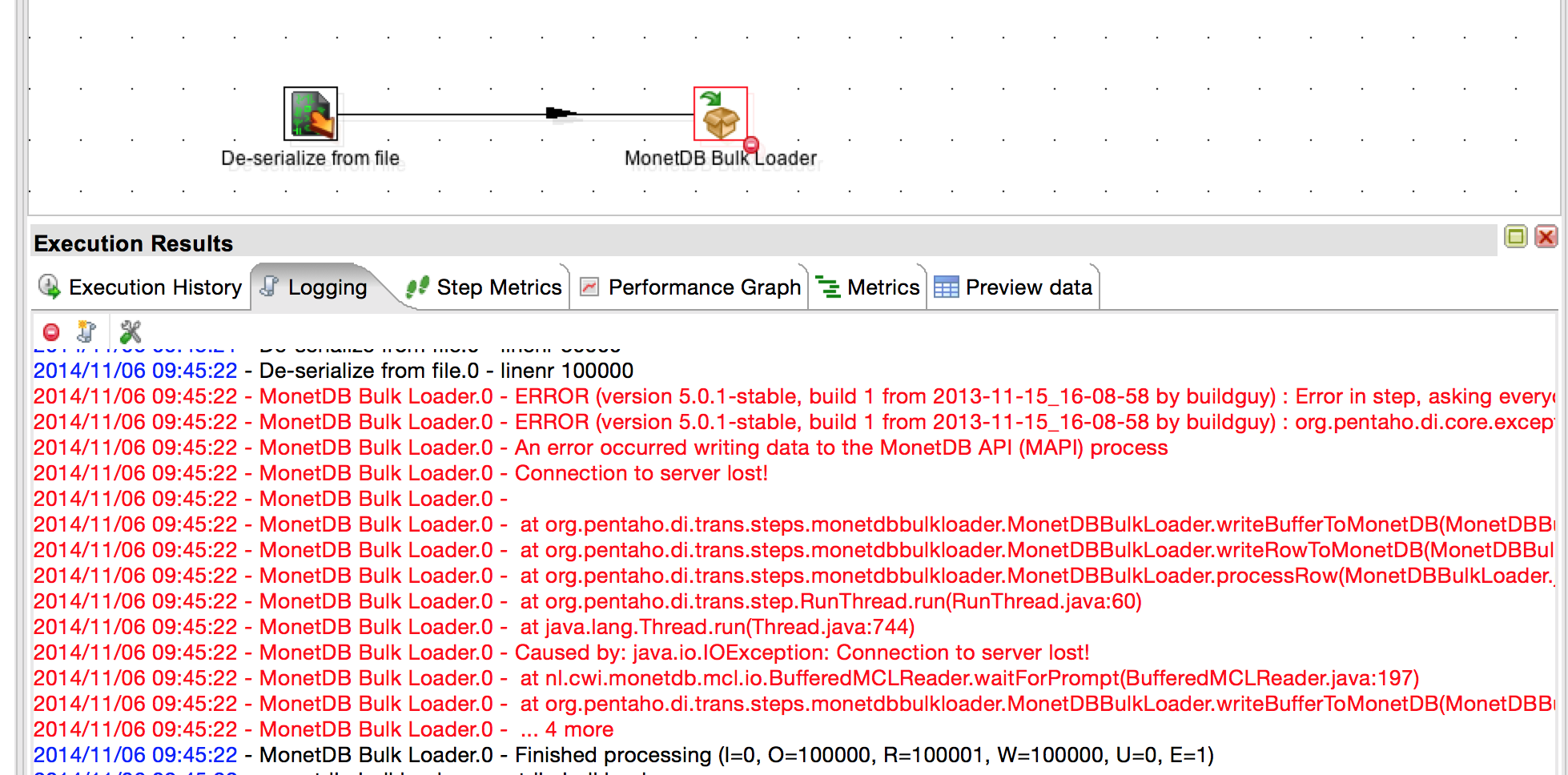
It works quite nicely and… oh, wait, it doesn’t work anymore. Apparently something is broken with the bulk load step. It does get the rows through up to whatever you defined as the buffer size, but then it blows up. So, in this case it loaded 100k rows and threw an exception after that. If you increase the buffer size to 500k rows it’ll load 500k rows and blow up on row 500001. And so on.
Obviously this is a problem. If your target DB is MonetDB you have two options to load the data via PDI: the slow Table Output or the much faster MonetDB bulk loader, which is broken.
After some googling I found a JIRA issue filed describing exactly the same problem (PDI-12278) and it also suggested a code change to fix it. The issue was reported in May and it’s on the backlog, so it’s not likely it’ll make it to a release anytime soon and I needed the step working now, so I decided to test the fix. As it happens, it works very nicely.
Now, I’m not a Java dev. In fact, I can’t even read Java code, let alone write it. So I decided to write this to explain to the non-devs around what you need to do to get the bulk loader step working.
I assume you have a Linux/Unix/Mac machine to do this. If you’re running Windows you should: a) Switch to a decent operating system; b) failing that, install Cygwin and all the packages required for this to work (e.g., you’ll need xmltasks as least, but last time I used Cygwin on a Windows box to build anything was some 4 years ago, so don’t take my word for it).
Step 1: Get the code
From your shell just clone PDI from the Github repo:
$ git clone https://github.com/pentaho/pentaho-kettle
Step 2: Build it
$ cd pentaho-kettle
$ ant dist
While this is building, grab yourself a cup of coffee and wait. It may take up to 1 hour to download all the required dependencies.
Check that you get Build successful in the end.
Step 3: See if it works
$ cd dist
$ ./spoon.sh
If it doesn’t run, most likely something is wrong with your environment, or the build failed somewhere. Go back to step 2 and fix whatever is the problem.
Step 4: Change the code, build again
$ cd engine/src/org/pentaho/di/trans/steps/monetdbbulkloader
$ nano MonetDBBulkLoader.java
Comment out lines 505-511 (WARNING: obviously, as more code is committed to the repository, the line numbers may change. Below you have what the code should look like, with a few lines before and after for context; easy way to find the code snippet you need to change? search for “again…”, there’s a single occurrence)
// again...
error = data.in.waitForPrompt();
if ( error != null ) {
throw new KettleException( "Error loading data: " + error );
}
// COMMENT FROM HERE
// data.out.writeLine( “” );
// and again, making sure we commit all the records
// error = data.in.waitForPrompt();
// if ( error != null ) {
// throw new KettleException( “Error loading data: ” + error );
// }
// TO HERE
if ( log.isRowLevel() ) {
logRowlevel( Const.CR );
}
Save the file and build it again.
Step 5: Test to see it works
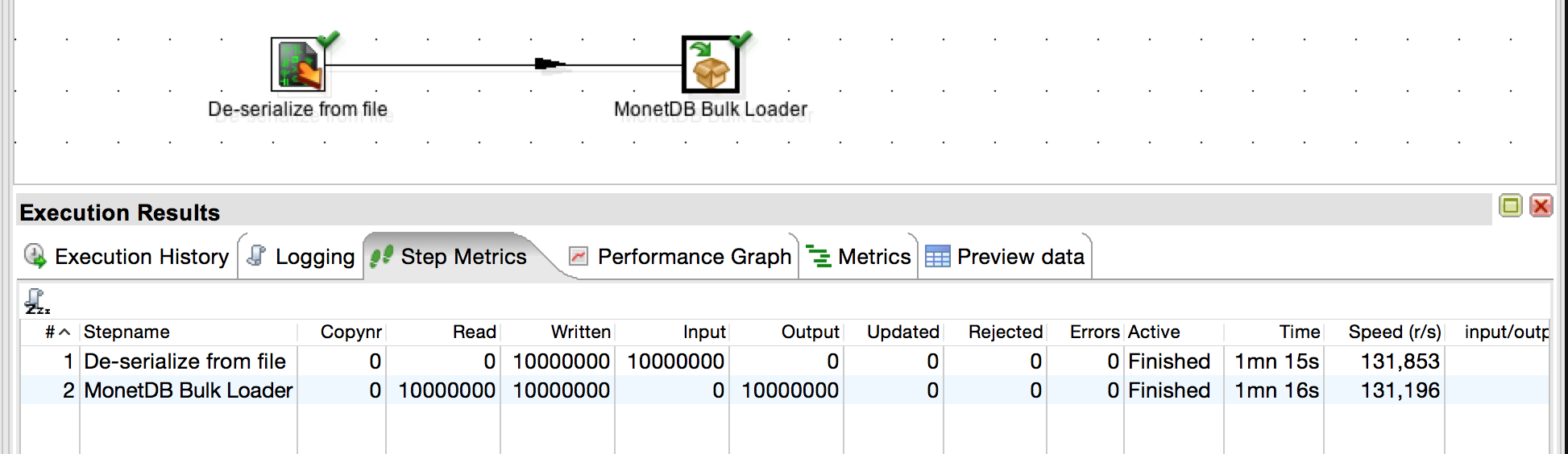
It’s working nicely and loaded all 10M rows in about 1’15” (the upload was done to a remote server some 3 countries away, not localhost, hence the relatively slow load speed).
Step 6: Apply the patch to a release version of PDI, instead of using trunk-snapshot
The previous steps allowed us to test the patch on the trunk-snapshot version of PDI. Most likely, this is NOT the version of PDI you want to run. You may want it for example, in PDI 5.2. What we need to do now is unpackage the JAR file where the MonetDBBulkLoader class is, copy it to the same location on the release version and then repackage.
For those that don’t knot the least bit about java, all those JAR files inside an application folder (e.g., the lib folder of PDI) are just archive files. You can unzip them to see what’s inside.
So first, lets copy the trunk-snapshot file to somewhere nicer and unpack it. Lets assume you have a ~/temp folder you want to use
$ cd lib
$ cp kettle-engine-TRUNK-SNAPSHOT.jar ~/temp/
Now do the same for your release PDI kettle engine (just replace <version> by your PDI version and build numbers)
$ cd /lib
$ cp kettle-engine-<version>.jar ~/temp/
Unzip both files:
$ cd ~/temp
$ mkdir trunk-snapshot
$ mkdir release
$ unzip kettle-engine-TRUNK-SNAPSHOT.jar -d trunk-snapshot
$ unzip kettle-engine-<version>.jar -d release
No copy the class you want from the snapshot folder to the release folder,
$cp trunk-snapshot/org/pentaho/di/trans/steps/monetdbbulkloader/MonetDBBulkLoader.class release/org/pentaho/di/trans/steps/monetdbbulkloader/MonetDBBulkLoader.class
Repack the release jar file:
$cd release
$jar cmf META-INF/MANIFEST.MF ../kettle-engine-<version>.jar *
Finally, grab your brand new kettle-engine JAR file and copy it to the lib folder of your PDI (remember to backup the original one, just in case).
Step 7: test that it works
Your MonetDB bulk loader step should now work in your 5.2 PDI version.
WARNING: This step by step guide is provided as-is. It was tested on PDI CE 5.2 and worked for me. That does not asure it will run for everybody, nor across all versions or all platforms. Use it at your own risk and remember to backup your original files first. If you spot an error or a typo on this post, please leave a comment and we’ll change it.


2 Comments
Thank you so much for the solution. You saved my day 🙂
Fyi, that JIRA is marked as fixed in PDI 5.4.0.